Route AI requests to 50+ providers with one endpoint
BETAOne API, Every LLM Provider. Intelligent fallback, circuit breaking, response caching, and deep analytics.
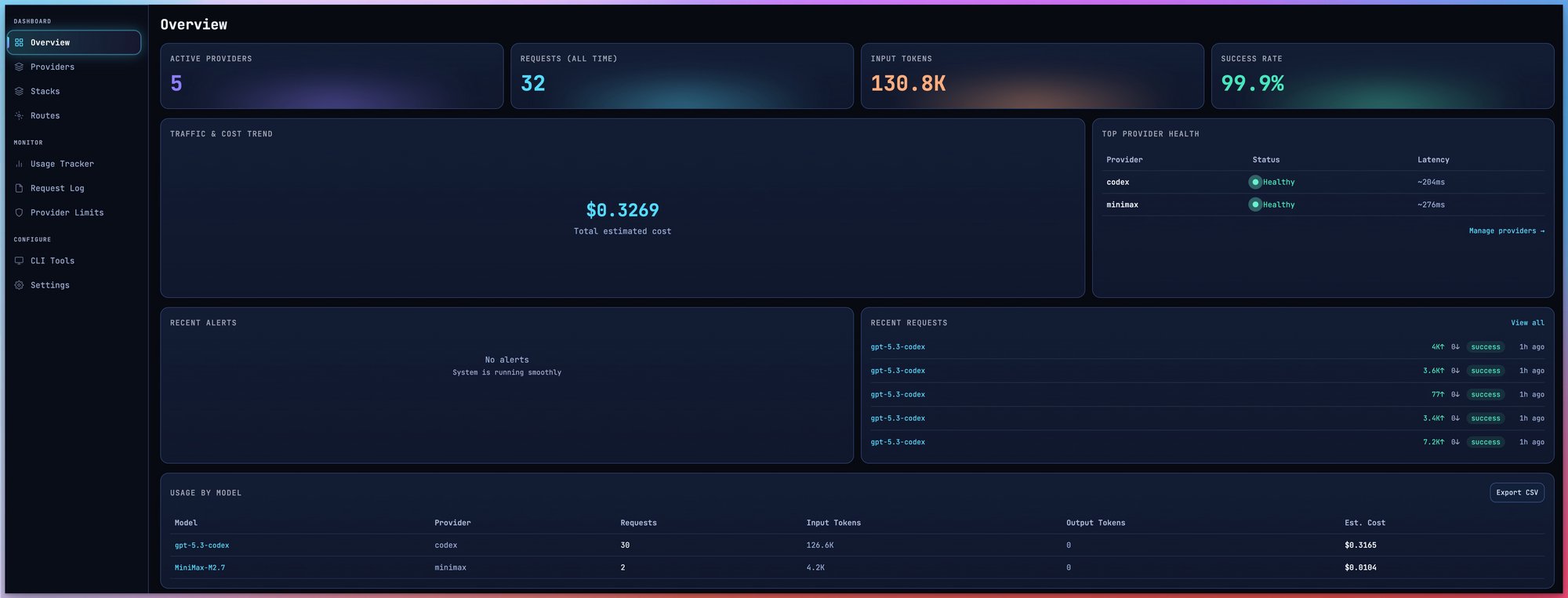
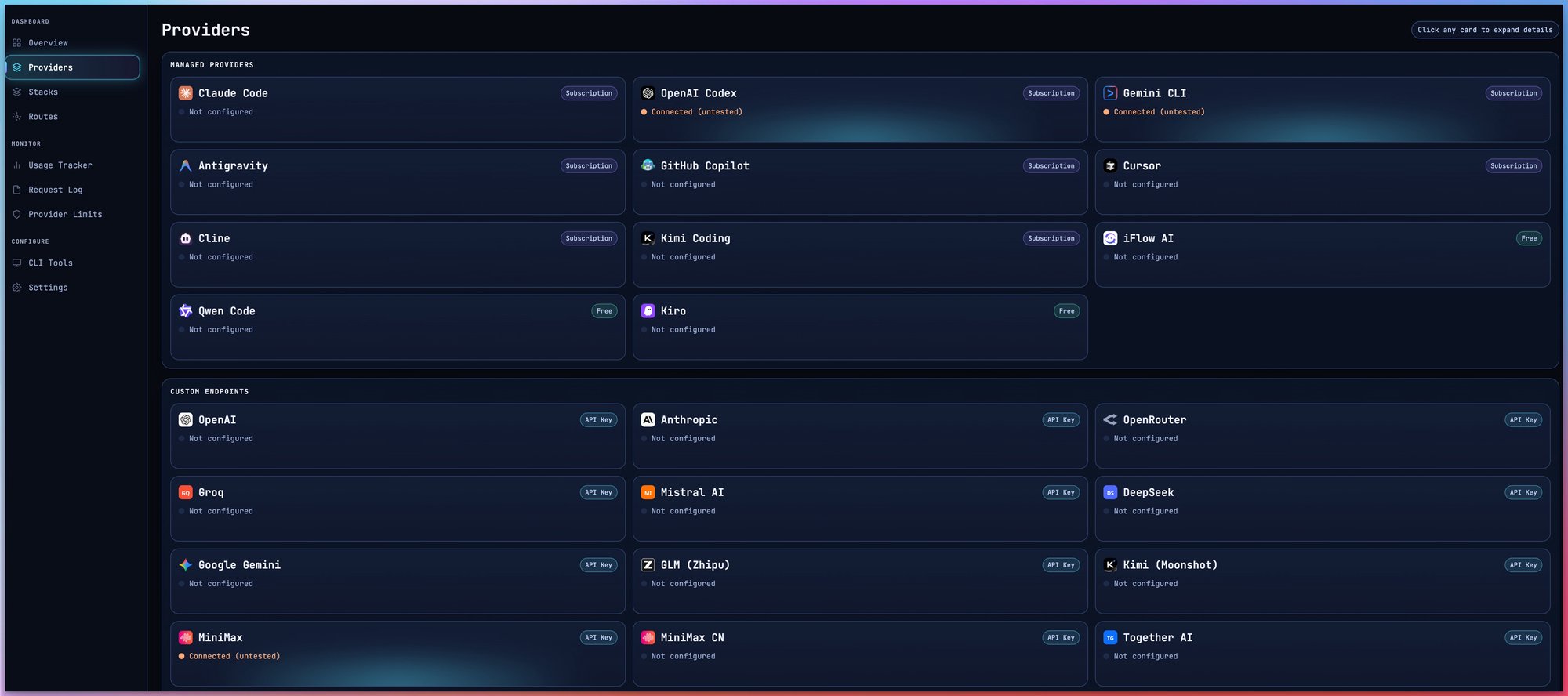
A Dashboard You'll Love
Monitor everything from one place — providers, analytics, stacks, and more.
Trusted by developers using
 OpenAI
OpenAI Anthropic
Anthropic Gemini
Gemini DeepSeek
DeepSeek Groq
Groq Mistral
Mistral xAI
xAI Cohere
Cohere NVIDIA
NVIDIA Perplexity
Perplexity Together
Together OpenRouter
OpenRouter Fireworks
Fireworks Cerebras
Cerebras SiliconFlow
SiliconFlow Nebius
Nebius Qwen
Qwen MiniMax
MiniMax Kimi
Kimi Ollama
Ollama GLM
GLMWorks with your favorite coding tools
Any OpenAI-compatible tool works out of the box

Claude Code
Anthropic's official CLI for Claude

Cursor
AI-first code editor

Cline
Autonomous coding agent for VS Code

Kilo Code
Lightweight AI coding assistant

Codex CLI
OpenAI's terminal-based assistant

Kiro
Agentic IDE by AWS

OpenCode
Terminal-based AI coding tool

Continue
Open-source AI code assistant

Roo Code
AI pair programmer

GitHub Copilot
AI-powered code suggestions

Droid
AI code assistant for Android
Antigravity
AI coding accelerator
Everything you need to route smarter
Production-grade infrastructure for AI applications
Intelligent Routing
Latency-optimised, cost-optimised, or balanced strategies with real-time provider scoring and automatic failover.
Circuit Breaker
Automatic OPEN/HALF-OPEN/CLOSED state machine per provider. Failing providers bypassed instantly.
Response Cache
In-process LRU cache with SHA-256 keying. Identical requests return instantly — zero tokens consumed.
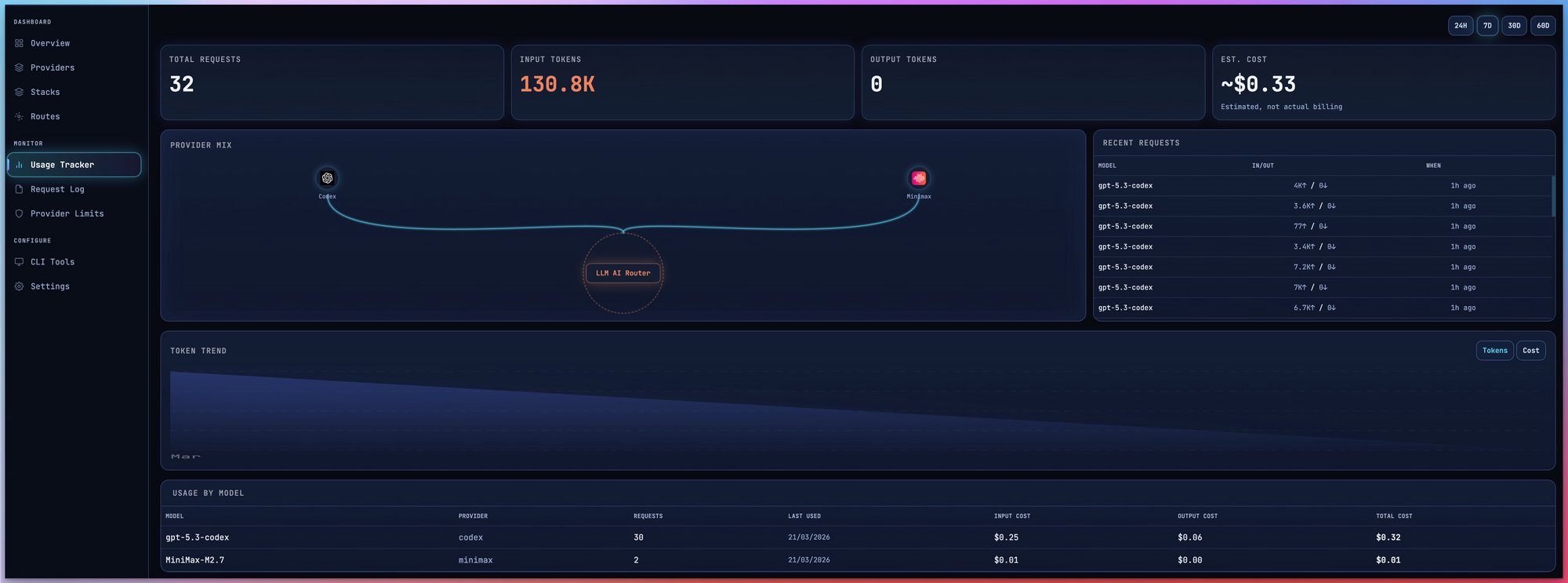
Deep Analytics
Time-series charts, cost breakdown, latency percentiles, quota tracking, and live request feed.
OpenAI-Compatible API
Drop-in replacement for Chat Completions endpoint. Point any tool at your router URL and go.
Zero-Knowledge Security
AES-256-GCM encrypted credentials. The server never sees your raw API keys.
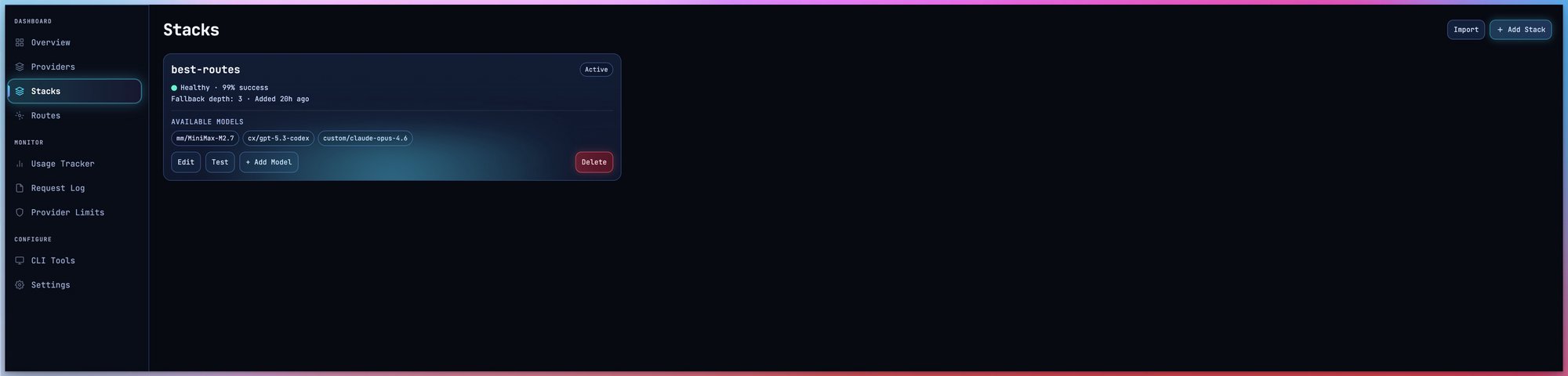
Stacks — Never Stop Coding
Build multi-tier provider groups with automatic fallback. When one provider hits its limit, the next one picks up instantly.
Claude Code ProOpenAI Codex Plus Gemini CLIDeepSeekGroqTogether AIOpenRouter free modelsGemini free tier
Gemini CLIDeepSeekGroqTogether AIOpenRouter free modelsGemini free tierTake Control of Your AI Costs
Track spending across all providers. Never waste a subscription token.
Real-Time Quota Tracking
Live token consumption per provider. Reset countdowns. Usage percentages at a glance.
Cost Breakdown
Per-provider and per-model cost analysis. Know exactly where your money goes.
Subscription Maximization
Track Claude Code, Codex, Gemini quotas. Use every token before it resets.
Smart Cost Routing
Set routing strategy to "cost" to automatically prefer the cheapest available provider.
Stop Wasting Your AI Subscriptions
LLM AI Router solves this:
Your API keys are safe. Period.
AES-256-GCM encryption at rest
Military-grade authenticated encryption protects every stored credential
Keys encrypted before storage
API keys are encrypted server-side before they ever touch the database
Never exposed
Keys never appear in logs, API responses, or database views
Decrypted only in-memory
Keys are decrypted momentarily when proxying a request, then immediately discarded
You own the encryption key
The ENCRYPTION_KEY is yours alone, stored only in your server environment
How it works
Three simple steps to smarter AI routing
Connect providers
Add API keys or OAuth accounts. Credentials encrypted before storage.
Build a stack
Define tiers of providers with fallback. Set routing strategy.
Point your tools
Set OPENAI_BASE_URL. Every request routed, cached, and logged.
One line to get started
Drop-in replacement for any OpenAI-compatible tool
Free to use. Bring your own API keys.
You pay nothing for the router. You only pay your AI providers directly. No hidden costs, no markup on tokens.